
![]()
MNIST 教程#
欢迎使用 Flax NNX!本教程将指导您使用 Flax NNX API 在 MNIST 数据集上构建和训练一个简单的卷积神经网络 (CNN)。Flax NNX 是一个基于 JAX 的 Python 神经网络库,目前作为 Flax 中的实验模块提供。
2. 加载 MNIST 数据集#
首先,使用 Tensorflow Datasets 加载 MNIST 数据集并准备用于训练和测试。图像值被归一化,数据被洗牌并划分为批次,并且样本被预取以提高性能。
import tensorflow_datasets as tfds # TFDS for MNIST
import tensorflow as tf # TensorFlow operations
tf.random.set_seed(0) # set random seed for reproducibility
train_steps = 1200
eval_every = 200
batch_size = 32
train_ds: tf.data.Dataset = tfds.load('mnist', split='train')
test_ds: tf.data.Dataset = tfds.load('mnist', split='test')
train_ds = train_ds.map(
lambda sample: {
'image': tf.cast(sample['image'], tf.float32) / 255,
'label': sample['label'],
}
) # normalize train set
test_ds = test_ds.map(
lambda sample: {
'image': tf.cast(sample['image'], tf.float32) / 255,
'label': sample['label'],
}
) # normalize test set
# create shuffled dataset by allocating a buffer size of 1024 to randomly draw elements from
train_ds = train_ds.repeat().shuffle(1024)
# group into batches of batch_size and skip incomplete batch, prefetch the next sample to improve latency
train_ds = train_ds.batch(batch_size, drop_remainder=True).take(train_steps).prefetch(1)
# group into batches of batch_size and skip incomplete batch, prefetch the next sample to improve latency
test_ds = test_ds.batch(batch_size, drop_remainder=True).prefetch(1)
/usr/local/google/home/cgarciae/flax/.venv/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
2024-07-10 15:24:11.227958: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-07-10 15:24:12.227896: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
3. 使用 Flax NNX 定义网络#
通过继承 nnx.Module 创建一个使用 Flax NNX 的卷积神经网络。
from flax import nnx # Flax NNX API
from functools import partial
class CNN(nnx.Module):
"""A simple CNN model."""
def __init__(self, *, rngs: nnx.Rngs):
self.conv1 = nnx.Conv(1, 32, kernel_size=(3, 3), rngs=rngs)
self.conv2 = nnx.Conv(32, 64, kernel_size=(3, 3), rngs=rngs)
self.avg_pool = partial(nnx.avg_pool, window_shape=(2, 2), strides=(2, 2))
self.linear1 = nnx.Linear(3136, 256, rngs=rngs)
self.linear2 = nnx.Linear(256, 10, rngs=rngs)
def __call__(self, x):
x = self.avg_pool(nnx.relu(self.conv1(x)))
x = self.avg_pool(nnx.relu(self.conv2(x)))
x = x.reshape(x.shape[0], -1) # flatten
x = nnx.relu(self.linear1(x))
x = self.linear2(x)
return x
model = CNN(rngs=nnx.Rngs(0))
nnx.display(model)
运行模型#
让我们对我们的模型进行测试!我们将使用任意数据执行前向传播,并打印结果。
import jax.numpy as jnp # JAX NumPy
y = model(jnp.ones((1, 28, 28, 1)))
nnx.display(y)
4. 创建优化器和指标#
在 Flax NNX 中,我们创建一个 Optimizer 对象来管理模型的参数,并在训练期间应用梯度。 Optimizer 接收模型的引用,以便它可以更新其参数,以及一个 optax 优化器来定义更新规则。此外,我们将定义一个 MultiMetric 对象来跟踪 Accuracy 和 Average 损失。
import optax
learning_rate = 0.005
momentum = 0.9
optimizer = nnx.Optimizer(model, optax.adamw(learning_rate, momentum))
metrics = nnx.MultiMetric(
accuracy=nnx.metrics.Accuracy(),
loss=nnx.metrics.Average('loss'),
)
nnx.display(optimizer)
5. 定义步骤函数#
我们使用交叉熵损失定义一个损失函数(有关更多详细信息,请参见 optax.softmax_cross_entropy_with_integer_labels()),我们的模型将优化它。除了损失之外,还会输出 logits,因为它们将用于在训练和测试期间计算精度指标。在训练期间,我们将使用 nnx.value_and_grad 计算梯度并使用优化器更新模型的参数。在训练和测试期间,损失和 logits 都用于计算指标。
def loss_fn(model: CNN, batch):
logits = model(batch['image'])
loss = optax.softmax_cross_entropy_with_integer_labels(
logits=logits, labels=batch['label']
).mean()
return loss, logits
@nnx.jit
def train_step(model: CNN, optimizer: nnx.Optimizer, metrics: nnx.MultiMetric, batch):
"""Train for a single step."""
grad_fn = nnx.value_and_grad(loss_fn, has_aux=True)
(loss, logits), grads = grad_fn(model, batch)
metrics.update(loss=loss, logits=logits, labels=batch['label']) # inplace updates
optimizer.update(grads) # inplace updates
@nnx.jit
def eval_step(model: CNN, metrics: nnx.MultiMetric, batch):
loss, logits = loss_fn(model, batch)
metrics.update(loss=loss, logits=logits, labels=batch['label']) # inplace updates
该 nnx.jit 装饰器跟踪 train_step 函数,以便使用 XLA 进行即时编译,从而优化硬件加速器的性能。 nnx.jit 类似于 jax.jit,只是它可以转换包含 Flax NNX 对象作为输入和输出的函数。
注意:在上面的代码中,我们对模型、优化器和指标进行了多次就地更新,并且没有显式返回状态更新。这是因为 Flax NNX 转换尊重 Flax NNX 对象的引用语义,并将传播作为输入参数传递的对象的状态更新。这是 Flax NNX 的一个关键特性,它允许编写更简洁、更易读的代码。
6. 训练和评估#
现在我们使用一批数据训练模型 10 个 epoch,在每个 epoch 后评估其在测试集上的性能,并记录整个过程中的训练和测试指标(损失和精度)。这通常会导致模型的精度约为 99%。
metrics_history = {
'train_loss': [],
'train_accuracy': [],
'test_loss': [],
'test_accuracy': [],
}
for step, batch in enumerate(train_ds.as_numpy_iterator()):
# Run the optimization for one step and make a stateful update to the following:
# - the train state's model parameters
# - the optimizer state
# - the training loss and accuracy batch metrics
train_step(model, optimizer, metrics, batch)
if step > 0 and (step % eval_every == 0 or step == train_steps - 1): # one training epoch has passed
# Log training metrics
for metric, value in metrics.compute().items(): # compute metrics
metrics_history[f'train_{metric}'].append(value) # record metrics
metrics.reset() # reset metrics for test set
# Compute metrics on the test set after each training epoch
for test_batch in test_ds.as_numpy_iterator():
eval_step(model, metrics, test_batch)
# Log test metrics
for metric, value in metrics.compute().items():
metrics_history[f'test_{metric}'].append(value)
metrics.reset() # reset metrics for next training epoch
print(
f"[train] step: {step}, "
f"loss: {metrics_history['train_loss'][-1]}, "
f"accuracy: {metrics_history['train_accuracy'][-1] * 100}"
)
print(
f"[test] step: {step}, "
f"loss: {metrics_history['test_loss'][-1]}, "
f"accuracy: {metrics_history['test_accuracy'][-1] * 100}"
)
2024-07-10 15:24:26.290421: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
[train] step: 200, loss: 0.3102289140224457, accuracy: 90.08084869384766
[test] step: 200, loss: 0.13239526748657227, accuracy: 95.52284240722656
2024-07-10 15:24:32.398018: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
[train] step: 400, loss: 0.12522409856319427, accuracy: 96.515625
[test] step: 400, loss: 0.07021520286798477, accuracy: 97.8465576171875
2024-07-10 15:24:38.439548: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
[train] step: 600, loss: 0.09092658758163452, accuracy: 97.25
[test] step: 600, loss: 0.08268354833126068, accuracy: 97.30569458007812
2024-07-10 15:24:44.516602: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
[train] step: 800, loss: 0.07523862272500992, accuracy: 97.921875
[test] step: 800, loss: 0.060881033539772034, accuracy: 98.036865234375
2024-07-10 15:24:50.557494: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
[train] step: 1000, loss: 0.063808374106884, accuracy: 98.09375
[test] step: 1000, loss: 0.07719086110591888, accuracy: 97.4258804321289
2024-07-10 15:24:54.450444: W tensorflow/core/kernels/data/cache_dataset_ops.cc:858] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
[train] step: 1199, loss: 0.07750937342643738, accuracy: 97.47173309326172
[test] step: 1199, loss: 0.05415954813361168, accuracy: 98.32732391357422
2024-07-10 15:24:56.610632: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
2024-07-10 15:24:56.615182: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
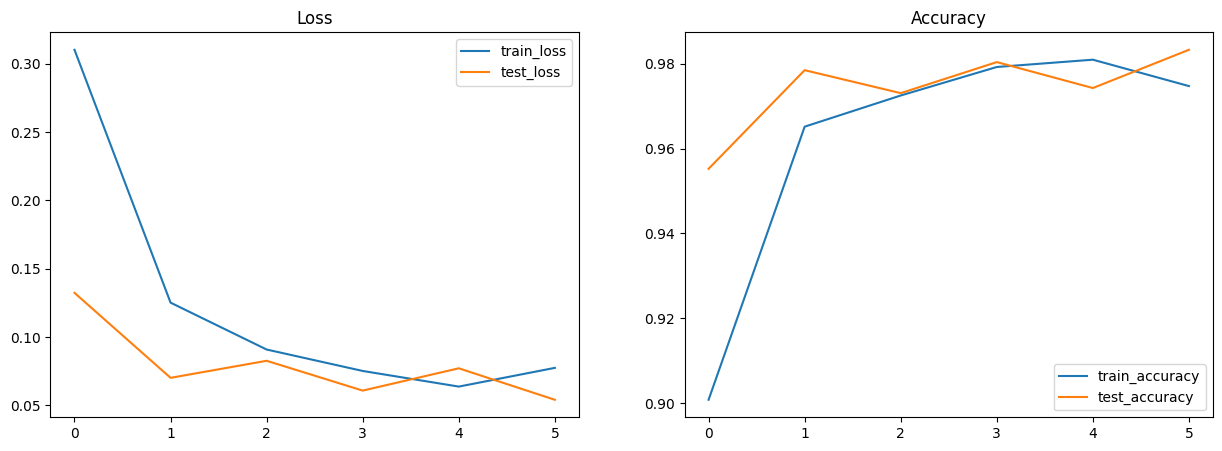
7. 可视化指标#
使用 Matplotlib 为损失和精度创建绘图。
import matplotlib.pyplot as plt # Visualization
# Plot loss and accuracy in subplots
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
ax1.set_title('Loss')
ax2.set_title('Accuracy')
for dataset in ('train', 'test'):
ax1.plot(metrics_history[f'{dataset}_loss'], label=f'{dataset}_loss')
ax2.plot(metrics_history[f'{dataset}_accuracy'], label=f'{dataset}_accuracy')
ax1.legend()
ax2.legend()
plt.show()
10. 在测试集上执行推理#
定义一个 jitted 推理函数 pred_step,使用学习到的模型参数在测试集上生成预测。这将使您能够将测试图像与其预测标签一起可视化,以定性地评估模型性能。
@nnx.jit
def pred_step(model: CNN, batch):
logits = model(batch['image'])
return logits.argmax(axis=1)
test_batch = test_ds.as_numpy_iterator().next()
pred = pred_step(model, test_batch)
fig, axs = plt.subplots(5, 5, figsize=(12, 12))
for i, ax in enumerate(axs.flatten()):
ax.imshow(test_batch['image'][i, ..., 0], cmap='gray')
ax.set_title(f'label={pred[i]}')
ax.axis('off')

恭喜!您已经完成了带注释的 MNIST 示例。